5. KNN
K邻近算法使用整个数据集作为训练集,而不是将数据集分成训练集和测试集。
当新的数据实例需要结果时,KNN算法遍历整个数据集,以找到新实例的k个最近的实例,或者与新记录最相似的k个实例,然后对于分类问题的结果(对于回归问题)或模式输出均值。
实例之间的相似度使用欧几里德距离和Hamming距离等度量来计算。
无监督学习算法:
6. Apriori
Apriori算法用于事务数据库挖掘,然后生成关联规则。它在市场篮子分析中被广泛使用,在这个分析中,检查数据库中经常出现的产品组合。一般来说,我们写出如果一个人购买项目X,然后他购买项目Y的关联规则为:X – > Y。
例如:如果一个人购买牛奶和糖,那么他很可能会购买咖啡粉。这可以写成关联规则的形式:{牛奶,糖} – >咖啡粉。
7. K-means
K-means是一种迭代算法,将相似的数据分组到簇中。计算k个簇的质心,并将一个数据点分配给质心和数据点之间距离最小的簇。
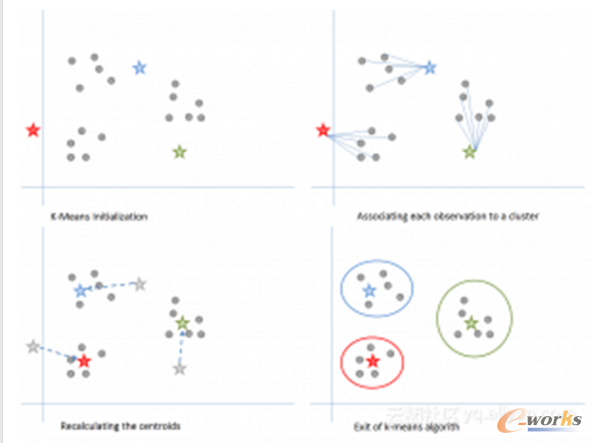
步骤1:k-means初始化:
a)选择k的值。在这里,让我们取k = 3。
b)将每个数据点随机分配到3个群集中的任何一个。
c)为每个集群计算集群质心。红色,蓝色和绿色星星表示3个星团中的每一个的质心。
步骤2:将每个观察结果与群集相关联:
将每个点重新分配到最近的集群质心。这里,上面的5个点被分配到具有蓝色质心的簇。按照相同的步骤将点分配给包含红色和绿色质心的群集。
第3步:重新计算质心:
计算新簇的质心。旧的质心由灰色星星表示,而新的质心是红色,绿色和蓝色星星。
第4步:迭代,然后退出,如果不变。
重复步骤2-3,直到没有从一个群集切换到另一个群集。一旦连续两个步骤没有切??换,退出k-means算法。
8. PCA
主成分分析(PCA)用于通过减少变量的数量来使数据易于探索和可视化。这是通过将数据中的最大方差捕获到一个称为“主要成分”的轴上的新的坐标系来完成的。每个组件是原始变量的线性组合,并且彼此正交。组件之间的正交性表明这些组件之间的相关性为零。
第一个主成分捕捉数据中最大变化的方向。第二个主要组件捕获数据中的剩余变量,但变量与第一个组件不相关。
9.随机森林装袋
随机森林是对袋装决策树(bagged decision trees)改进。
装袋(Bagging):装袋的第一步是创建多个模型,使用Bootstrap Sampling方法创建数据集。在Bootstrap Sampling中,每个生成的训练集由来自原始数据集的随机子样本组成。这些训练集中的每一个与原始数据集大小相同,但有些记录会重复多次,有些记录根本不会出现。然后,整个原始数据集被用作测试集。因此,如果原始数据集的大小为N,那么每个生成的训练集的大小也是N,测试集的大小也是N。
装袋的第二步是在不同的生成的训练集上使用相同的算法创建多个模型。在这种情况下,让我们讨论随机森林。与决策树不同的是,每个节点被分割成最小化误差的最佳特征,在随机森林中,我们选择随机选择的特征来构建最佳分割。在每个分割点处要搜索的特征的数量被指定为随机森林算法的参数。
因此,在用随机森林装袋时,每棵树都是使用记录的随机样本构建的,每个分叉是使用预测变量的随机样本构建的。
10. Boosting with AdaBoost
套袋(Bagging)是一个平行的集合,因为每个模型都是独立建立的。另一方面,boosting是一个连续的集合,每个模型的建立是基于纠正前一个模型的错误分类。
Adaboost代表Adaptive Boosting。

图9
在图9中,步骤1,2,3涉及一个称为决策残缺的弱学习者(一个1级决策树,仅基于1个输入特征的值进行预测)。步骤4结合了以前模型的3个决策树(在决策树中有3个分裂规则)。
步骤1:从1个决策树开始,对1个输入变量做出决定:
数据点的大小表明我们已经应用相同的权重将它们分类为一个圆或三角形。决策树在上半部分产生了一条水平线来分类这些点。我们可以看到有2个圆圈错误地预测为三角形。因此,我们将为这两个圈子分配更高的权重,并应用另一个决策树桩。
步骤2:移动到另一个决策树,以决定另一个输入变量:
我们观察到,上一步的两个错误分类圈的大小大于其余点。现在第二个决策树会试图正确预测这两个圆。
步骤3:训练另一个决策树来决定另一个输入变量。
来自上一步的3个错误分类圈大于其余的数据点。现在,已经生成了一条垂直线,用于分类圆和三角形。
步骤4:合并决策树:
我们已经结合了以前3个模型中的分隔符,并观察到这个模型中的复杂规则与任何一个单独的弱学习者相比,正确地分类了数据点。
本文为授权转载文章,任何人未经原授权方同意,不得复制、转载、摘编等任何方式进行使用,e-works不承担由此而产生的任何法律责任! 如有异议请及时告之,以便进行及时处理。联系方式:editor@e-works.net.cn tel:027-87592219/20/21。




















 需求中心
需求中心 AI助手
AI助手
 联系我们
联系我们