nanoFluidX只可以在Linux平台下使用支持CUDA的GPU显卡进行计算。CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
基于市场需求的驱动,高清3D显卡,可编程图形处理单元或者GPU已经演变成为高度并行、多线程、多核处理等彰显极大计算能力的特征;以及非常高的内存带宽。如图4、5所示。
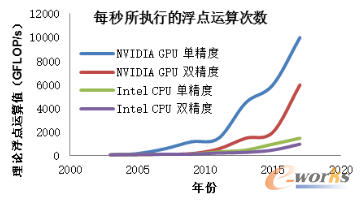
图4 GPU和CPU每秒所执行的浮点运算次数对比
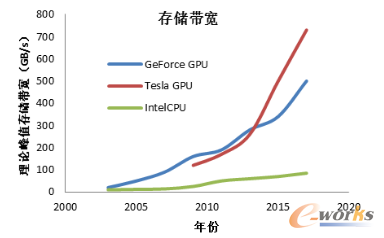
图5 GPU和CPU存储带宽对比
3 仿真建模及分析
3.1 仿真载荷与边界条件
此单速变速箱为二级减速齿轮箱结构。采用平行轴斜齿齿轮,比正齿轮强度高且运转平稳。同时,集成了差速器和驻车机构。如图6所示。

图6 单速电驱变速箱CAD示意图
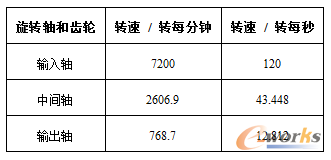
各个旋转齿轮轴的转速将作为润滑仿真的输入载荷。如表1,输入轴7200转每分钟等效于车速90千米每小时。
表1 齿轮轴转速信息
在nanoFluidX中有四种不同的相,或者可以把相理解为不同的SPH粒子类型;分别为FLUID、WALL、MOVINGWALL和MASSFLOW。仿真计算中,我们把变速箱壳体考虑为一个密闭的箱体,即Wall类型的SPH粒子。箱体中包含三个不同转速的旋转齿轮轴,即MOVINGWALL类型的SPH粒子。此案例需要考虑双相流,即箱体中的空气和润滑油,需要分别建立两组不同塑性的FLUID类型的SPH粒子。如图7所示。
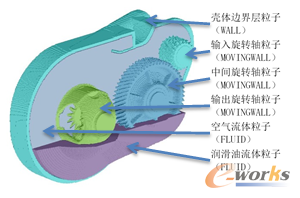
图7 粒子类型示意图
3.2 生成SPH粒子
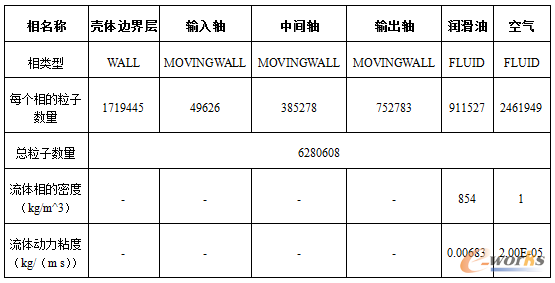
可以选择Simlab或者HyperMesh作为前处理软件。对于刚性墙,不管是WALL还是MOVINGWALL,只需要建立和流体粒子(FLUID)有相互作用力的边界层即可。如图2和图7所示,由于每一个粒子仅仅和相邻的粒子之间进行相互作用力的计算,所以边界墙建立了5层SPH粒子。流体粒子,包括空气和润滑油,需要填满封闭箱体。具体生成粒子的方法和过程这里就不再赘述,表2为生成的SPH粒子信息。
表2 SPH粒子信息
3.3 求解器设置
nanoFluidX的仿真配置文件为ASCII格式,目前只支持手工编辑。但是配置文件还是比较容易编写的,润滑仿真中只用了不到40个关键字卡片。配置文件分为通用仿真参数部分、求解域参数部分、核函数参数部分、相参数部分、运动参数部分和载荷平衡参数部分共计6个部分组成。nanoFluidX相对于传统基于网格法的CFD求解器更容易学习。在工程应用上或者说在软件操作上,不需要工程师花费太多的学习时间。软件的用户手册文档可以满足我们对理论背景和工程背景90%以上的需求;这大大减轻了工程师的学习负担。在此润滑仿真案例中,参考表1和表2中的转速信息、相信息、密度信息和黏度信息对仿真配置文件进行编辑。
3.4 ParaView后处理
ParaView是一个开源、多平台数据分析和可视化应用程序。用户可以采用定性和定量技术快速构建可视化分析数据。可以交互式地在3D和程序化之间使用ParaView的批处理能力进行数据探索。ParaView用C++编写,基于VTK(Visualization ToolKit)开发,而nanoFluidX目前仅支持VTK结果输出,即以pvd为扩展名的结果文件。
经过ParaView的后处理,可以从SPH粒子中获得和传统CFD求解类似的结果。例如,流体外观形状、速度云图、切片、时间历程属性统计(切片和流线)、向量标识、提取区域流体体积、沿直线的属性测量以及Shepard Coeff.等。
仿真模型总共运行了1秒,其中(0~0.1)秒为从0加速到7200转每分钟,(0.1~1)秒为保持恒定的7200转每分钟。输入轴转了114个循环。仿真计算用了5天5小时。图8为初始液面状态和仿真计算到1秒时的润滑油状态。

图8 初始液面状态和1秒时的润滑油状态
如下图9,在0.3秒以后,搅油功率损耗已经基本趋于稳定。虽然损耗扭矩结果有较大的浮动和噪点,但是仍然可以量化以及对比,总搅油功率损耗为240W左右。









